Interface Design Overview
API Types
This distribution does not support multi-threaded programming due to space constraints of the target platforms. Instead, asynchrony and concurrency are handled through callbacks. All of the APIs in this offering fall into one of the following categories.- Function call with no callback.
- Function call with callback capability. This requires 3 additional arguments in the function signature:
- a function pointer: callback handler registration If NULL is passed, the next two arguments are ignored. The call may fail return -1 or may succeed and return 0 without generating any notification.
- a type specific pointer to hold callback arguments: instead of providing callback arguments via function signature, data structures are used to hold the callback arguments. Caller allocates the structure, with the type defined by the particular function call, passes the pointer during the call, and the results will be stored in the structure upon the callback. If NULL is passed, the call may fail and return -1 or may succeed and return 0 for callback that takes no argument or callback that tolerates the caller to not take any callback arguments. Note that for the case of no argument callback, this automatically functions the same as a user context pointer described in the following next item.
- a user context pointer: this provides the convenience for users to maintain context along with continuation. The kernel merely passes the pointer along the continuation callback.
- Callback handler. All handlers from our APIs take the following function signature.
- Parameters:
-
event passed by the kernel to specify the type of event and potential error information using event_t. cbargs pointer to the return argument data structure passed to the kernel during call time context pointer to the user context passed to the kernel during call time
- Note:
- event allows callback handler to inspect what function call the handler binds to originally. This is done by using the function enumeration name defined in EventsEnum and check it against event.type. Below is an example showing how a handler can tell the callback is originated from a timer function call. The subtype field in event is defined by the function call itself.
- Kernel and Interrupt Notifications. All notifications take the same function signature as the callback handler. A call must be made to bind a particular type of kernel or interrupt notification and to a function handler. This binding may recur instead of being just a one-time notification. The binding is removed when an explicit call (e.g. stop or unbind) is made to not receive this particular kernel notification.
Main() Entry Point
The first user code entry point from the kernel is a kernel notification with the name __main().
void __main(event_t event, void * cbargs, void * context)
Since this shares the same signature as any callback handler in our APIs, one can reuse this same handler over and over again to create a continuation loop.
Error Handling
All function calls return 0 for success. All function calls fail by returning -1 and setting errno appropriately except for those that can be called within the interrupt context. These special calls are defined in async.h and they return the appropriate errno when error occurs.Callback handler may entail call-specific error information in data structure specified in cbargs. Kernel notifications may entail error information by setting event.error to event.errno appropriately.
Concurrency Model
Our kernel library provides a single-threaded event driven concurrency model, with each event realized as a callback handler scheduled by our kernel's scheduler. The scheduler ensures that callback handlers are atomic with respect to each other. That is, no callback can run until the current callback handler is completed.- Note:
- This strictly requires that each callback handler must run into completion, which means writing a while(1) loop in the handler can hang the entire system.
Interrupt Context
Our APIs cannot be called in the interrupt context except for those that schedule a continuation in the kernel context or those that control global interrupts for atomicity.Our offering relies on timer and SPI interrupts to drive the network stack and kernel services. The design guideline is to handle fast process in interrupt context and schedule a continuation in the application context for more involved processing. This is exemplified by the following diagram.
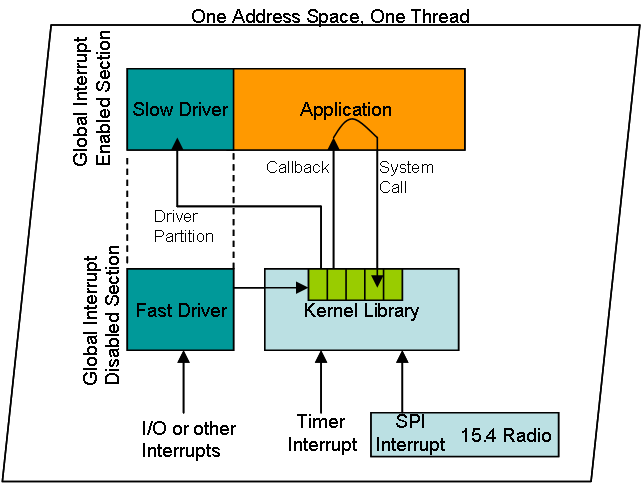
Overall Concurrency Diagram
A driver is usually written in two parts. One is within the interrupt context, where fast actions are required to be serviced. Heavy processing will continue in the application level context by scheduling a callback through the scheduler.
Busy waiting to handle I/O is possible within a callback handler as long as the busy waiting loop does not run "indefinitely". Like any event-driven systems, long busy waiting loop within a callback handler can take control of the system. To avoid the situation, one can utilize a timer to poll for an I/O event periodically to avoid waiting for I/O within an infinite loop.
The kernel owns the SPI bus, the necessary I/O pins, and interrupts to drive the 15.4 radio. It also uses a subset of hardware timers to support its time service. The kernel may also use a subset of other interrupt vectors, which driver developers may need to get shared access. This is a common case for some platforms in which the same interrupt vector may be mapped to more than one kind of interrupt. These interrupts are all listed in platform.h
For these interrupts, the kernel will service interrupt handler if it is intended for the kernel. Otherwise, the kernel will ignore it and notify the application if there is an user interrupt handler binds to this interrupt. Refer to async.h to see how to bind an interrupt handler with the kernel. Note that once a user interrupt handler has called the bind function to an interrupt shared with the kernel, it will always get notified whenever the underlying interrupt fires, even if the firing is intended for the kernel. This is to simplify the kernel for small footprint rather than administrating filtering mechanism. Therefore, it is recommended that user defined interrupt handlers that share interrupts with the kernel should double check the interrupt flags to ensure the user is servicing the interrupt that he or she desires.
The list of interrupts used by or shared with the kernel is listed in platform.h. For other interrupts, user can connect to the interrupt vector directly.
Hardware Abstraction Layer
We do not offer any hardware abstraction layer on the processor except the internal on-chip non-volatile storage. Developers must create the relevant code themselves to access the peripherals and link it up to the kernel library.Resource Descriptor Model
Resources that have multiple instances would require a file descriptor access model. These include socket, timer, and scheduling for a continuation in application context. When the number of instances for each type of resources has reached its limit, application must close some opened ones for reuse. Refer to RELEASE_NOTES to learn the limits.Memory Handling and Allocation
The kernel does not provide dynamic memory APIs. All memory should be statically allocated.Memory ownership of cbargs in callback handlers is returned back to the application upon the firing of the callback function. Kernel never owns the memory region pointed by context. It is purely intended for user context.
For callbacks that bind a resource descriptor with a callback handler, cbargs is owned by the kernel until the resource is closed explicitly by a call. Thus, application must copy contents of the cbargs during each callback instance if it desires to retain the information.
Similarly, calls that explicitly require application buffers to operate require binding the buffer to a resource descriptor initially. The resulting buffer is released back to the application when the resource is closed explicitly.
UDP Fragmentation Buffer and TCP Queue Buffer
Our kennel library handles buffer queuing for both UDP and TCP communications and buffers are passed to the kernel through either udpbind or tcpbind calls.For UDP, the buffer used is purely for fragmentation such that an application buffer is used to support a single application data unit (message) that is larger than the supported maximum transfer unit (MTU in net_device_info.device) in 15.4 radios. The buffer is used for the underlying mechanism to support link-layer fragmentation and reassembly. If no fragmentation is used, no buffer is required to pass down for UDP communications.
For TCP, the goal is to use an application buffer to queue up the byte streams for transmission and reception. Applications may want to adjust the buffer size, depending on the amount of backlog it expects or observes with its intended bandwidth requirement. Ideally, users should choose a large enough buffer so that they do not have to manage buffer back-pressure themselves. When back-pressure does occur, users may need to do some additional buffering of data above TCP and rely on notifywrite from the kernel to notify the user that more buffering is available for transmission.
Power Management
Power management of the radio and process is handled automatically by the kernel library. Application can override the policy and keep the CPU from sleeping. Duty-cycling powering of the radio can also be controlled separately. Application can be notified before processor goes to sleep each time if an handler is installed through kernel services in svcs.h.Watchdog and System Reboot
Application can reboot the system via a kernel service call or it can get a notification that a reboot is about to start when such reboot is administrated by remote Arch Rock management tools.Applications can get notification for each watchdog event in the kernel to guard against its own invariant. The frequency of the watchdog event is controlled by the kernel and is chosen to be 0.5 second. So, application only gets notified for each watchdog event. If some invariants fail, application needs to explicitly call reboot through kernel services.
